Choosing the most appropriate forecasting method for your time series is not a trivial task and even though there has been scientific forecasting for so many decades, how to best do it is still an open research question. Nonetheless, there are some reasonable ways to deal with the problem, which although they may not be perfect, they can certainly provide very reasonable results and help you automate the forecasting process.
I will not attempt to provide a textbook style description of how to do it, but I will try to provide you some of the basic alternative approaches, paying additional attention to common mistakes that I have seen in industry and practice.
First, we need to have clear objectives:
- What do we need to forecast?
- What is the criterion or criteria of success?
- What is the relevant forecast horizon?
These may sound like common sense, but perhaps the most common misconception I come across in companies is that they expect a single forecasting method to be good at producing forecasts for all short, medium and long forecast horizons. This is an `optimistic’ way of looking at forecasting, which will often result in poor forecasts for some of the horizons.
1. A general approach: using a validation sample
Statistical forecasts require past historical data, which we can use in many ways. Suppose we have a monthly time series with 5 years of data and our objective is to forecast the future demand six months in the future. As it can be seen in Fig. 1 the time series is clearly seasonal and trending. As such two alternative forecasts have been build, one using Exponential Smoothing and one using ARIMA (there is no need to go in the model details).

Fig. 1: An exponential smoothing (ETS) and ARIMA forecast.
Both forecasts seem reasonable and close enough to be able to judge which one to pick just by visually inspecting them. A statistically sound way to do this is to split the series into two parts, one to fit the model and one to validate how well it forecasts and pick the model that is the most accurate. Fig. 2 demonstrates this. The models are fit in the first part of the series and the validation set is not used at all for this. Then out-of-sample forecasts are produced and compared with the values in the validation set, as if these were true future forecasts. This is why it is also important to not use any of that data for the model building.
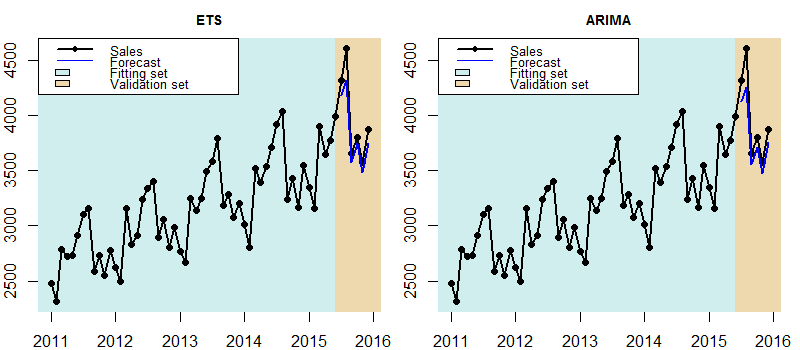
Fig. 2: ETS and ARIMA forecasts on validation set. The models are fitted only in the first part of the time series and the validation set is used only to assess their performance.
We can then measure the accuracy of the forecasts on the validation set and pick the best performing model. In this example I do this by measuring the Mean Absolute Error (MAE), which indicates that ETS is the best.
| Model | MAE |
|---|---|
| ETS | 132.15 |
| ARIMA | 160.85 |
The example above is quite easy to repeat with as many forecasting methods as needed, considering even judgmentally generated or adjusted forecasts. However there is an issue with it, we are relying our choice on a single measurement. This is risky, as we may be very (un)lucky on this measurement and it may not be representative of the normal behaviour of the forecasting methods. To mitigate this problem we should perform a rolling origin evaluation on the validation set. To do this we need to use a validation set that is longer than the target forecast horizon and then follow these steps:
- Produce a forecast for 6 steps ahead
- Increase the fitting sample by one period (so the first point of the validation set is moved to the fitting set and the validation set is smaller by one period)
- Refit the model in the new fitting set
- Go back to step 1. and repeat until all the validation set is exhausted, i.e. no more forecasts of 6-periods ahead can be evaluated.
In this example we could use 18 months as a validation set. This way we can produce 18 – 6 + 1 = 13 6-step ahead forecasts, spanning 1.5 years of data and get a more reliable measurement of the MAE, as is shown in Fig. 3.

Fig. 3: Rolling origin forecasts. Forecast from each origin are plotted with different colours.
Observe that the second ARIMA forecast is rather poor (a straight like that does not follow the seasonal shape). This is also reflected in the errors for each forecast origin that are reported in the following table. We can see that although ETS is not always best (ARIMA is best for origins 6, 7 and 8), on average it is. If we would have looked at only a single forecast we could potentially end up selecting ARIMA instead. Looking at multiple forecasts gives us confidence to choose the overall best and therefore ETS is more reliable and should be used to produce any future forecasts.
| Origin | ETS | ARIMA |
|---|---|---|
| 1 | 76.81 | 106.00 |
| 2 | 81.77 | 467.16 |
| 3 | 86.71 | 123.83 |
| 4 | 85.93 | 114.76 |
| 5 | 93.09 | 103.62 |
| 6 | 95.11 | 82.90 |
| 7 | 83.44 | 71.80 |
| 8 | 99.23 | 82.21 |
| 9 | 107.55 | 116.51 |
| 10 | 100.13 | 123.03 |
| 11 | 108.71 | 137.62 |
| 12 | 109.88 | 147.90 |
| 13 | 132.15 | 160.85 |
| Average | 96.96 | 141.40 |
Using a validation sample does not impose any particular restrictions in terms of what forecasts can be compared, but it is obvious that we need to `sacrifice’ sample for the validation set. This sample could be used to build better forecasts as part of the fitting set.
2. A more specialiased approach: Information Criteria
An alternative is to use what is called Information Criteria (IC). There are many criteria and the most common are Akaike’s Information Criterion (AIC) and Bayesian Information Criterion (BIC). Before explaining what IC do let us keep in mind that a more complex model is typically able to fit better to past data, to the extend it may overfit. If it overfits then it will not produce good forecasts for unseen future data. So we do not want to select the model that has the lowest forecast error in the fitting sample, as it may just have overfitted. Note that using a validation set avoids this problem by measuring the forecasting accuracy in a different sample altogether: the validation set. For an example of what overfitting is you can check this.
IC try to balance how good a model fits and its complexity. In general IC are of the following form:
IC = goodness of fit + penalty for model complexity.
Model complexity is typically the number of model parameters scaled by some factor to make it comparable to the goodness of fit metric, which itself is based on the idea of the likelihood function. I will try to avoid providing an explanation of what likelihood is, and continue to provide the definition of AIC (you can skip the equations without missing the logic):
}")
where k is the number of model parameters, ln is the natural logarithm and L is the likelihood function. Under conditions (the residuals to follow independent identical normal distributions with zero mean) the maximum likelihood estimate for the variance (σ) of the model residuals is equal to the Mean Squared Errors (MSE):
^2}")
where y are the actuals, f the forecasts and n the sample size. Using that we can write:
=-\frac{n}{2}ln{(2\pi)} -\frac{n}{2}ln{(\sigma^2)} -\frac{n}{2\sigma^2}MSE = -\frac{n}{2}ln(MSE) + C")
where C is a constant that depends only on the sample that is used and not the forecasting model. This is a critical point that I will return to later. This in turn gives:
}=2k -2 (-\frac{n}{2}ln(MSE) + C_1) = 2k + nln{(MSE)} - 2 C")
Since the aim is to measure the AIC between two models fit on the same data, we are interested in the differences between two AICs that will have the same –2C, so we can safely ignore this term and finally write:
")
This views allows us to clearly see how AIC works (if you skipped the equations you want to start reading again here!). A model that fits well will have small MSE. If to do that it needs a lot of model parameters (complexity) then the term 2k will be large, thus making AIC larger. The model with the smallest AIC will be the model that fits best to the data, with the least complexity and therefore less chance of overfitting. BIC is similar in construction, but imposes an even stricter penalty for the number of parameters.
The beauty of ICs is that since the chance of overfitting is accounted in the metric explicitly there is no need for a validation sample. This leaves more data for model fitting. The downside it that the sample over which is calculated has to remain the same. Changing the number of data points, transforming the sample or in any way manipulating it invalidates the comparison (due to the calculation of the constant C1 and MSE). This is why ICs often come with the warning: use ICs only within a single model family. This is actually misleading, but often enough to make people use it correctly. For example we can use AIC to compare between different exponential smoothing models, but not between exponential smoothing and ARIMA models. The reason is that there is a good chance somewhere in the modelling the sample will be manipulated in a way that it will invalidate the comparison. For readers who are familiar with ARIMA models also consider that we should not use ICs to compare ARIMA(p,0,q) and ARIMA (p,d,q) for d>0, as the differenced data have different sample size and scale to the original observations.
For example, let us compare two similarly looking exponential smoothing models: ETS(M,A,M) and ETS(M,Ad,M); the latter using damped trend which requires an additional model parameter. The model fits and forecasts are shown in Fig. 4, where we can see that they look almost identical.

Fig. 4: Forecasts using two exponential smoothing models.
The AIC values for these are:
| Model | AIC |
|---|---|
| ETS(M.A.M) | 767.30 |
| ETS(M.Ad.M) | 770.41 |
ETS(M,A,M) is preferable (minimum AIC), as the additional parameter does not offer any substantial fitting benefits. Obviously both forecasts are practically the same, so this comparison is only useful as an example. Nonetheless, given the large variety of exponential smoothing models (type of trend, type of seasonality, type of error term), using ICs can help us to quickly pick the best model form without losing data to the validation set. But this comes at the cost that we can only use ICs when the data do not change (or as it is commonly said: within a single model family). Note that the data may be changed by the model internally, without the user being aware, so when in doubt avoid!
3. Avoid selection altogether: combine forecasts
Another approach that is quite popular in research is to avoid selecting a single forecast altogether. We can do this by combining forecasts. Returning to Fig. 1 we can take the values of both forecasts and calculate the arithmetic mean for each period:
| Forecast | Jan | Feb | Mar | Apr | May | Jun |
|---|---|---|---|---|---|---|
| ETS | 3586.245 | 3397.946 | 4204.788 | 3981.081 | 4101.305 | 4394.184 |
| ARIMA | 3678.148 | 3491.572 | 4233.729 | 3983.787 | 4108.809 | 4327.817 |
| Combined | 3632.196 | 3444.759 | 4219.259 | 3982.434 | 4105.057 | 4361.000 |
We can combine the forecasts from as many sources as desirable. Furthermore, there are many different ways to combine forecasts. although the simple arithmetic mean often works remarkably well. There is a lot of evidence demonstrating that forecast combination leads to very reliable and accurate forecasts. If you want you can explore further this paper that introduces several combination methods and evaluates their performance in terms of forecasting and inventory management.
4. Concluding remarks
Using a validation set or information criteria are two common approaches to select the best forecast. Each has its advantages and disadvantages. Using a validation set is general and can be used to compared forecasts from any source, but comes at a cost of sample size. On the other hand we can use information criteria without withholding any data for the validation set, thus permitting better model specification, but can only be used within the same model family and requires the forecasts to come from a formal statistical model, so that the likelihood function can be calculated. These are not the only two ways to select forecasts, other approaches such as meta-learning exist, but none is perfect in every aspect.
Personally I used to like the idea of a single `correct’ model. This also has the advantage that with a single model it is often very easy to get prediction intervals or use the model coefficients, for example to calculate elasticities. However, I nowadays have warmed to the idea of forecast combinations, since there is no need to rely on a single forecast. Why should we put all our trust on a single specific model that is fit in past data to forecast the future? I would rather hedge my risk and use multiple forecasts. Of course, it is also convenient that combined forecasts are often quite accurate!
Pingback: Using information criteria to select forecasting model (Part 1) - The Business Forecasting Deal
Pingback: Using information criteria to select forecasting model (Part 1) - supplychain.com
Pingback: Using information criteria to select forecasting model (Part 2) - supplychain.com
Pingback: Using information criteria to select forecasting model (Part 2) - The Business Forecasting Deal
Thank you for the article, but I am not sure I understand how to estimate number of parameters for exponential smoothing. If I want to compare models with different alpha (smoothing factor changing from 0 to 1), then in Information criteria I want to penalize cases where alpha is close to 1 and we almost follow the signal (may be considered as overfitting). Sorry if I missed something
Information criteria will not penalise specifically for the value of the smoothing parameter. Let us consider, for example, the case of the single exponential smoothing (or local level model – ETS(A,N,N)). This has the following parameters that need to be optimised: the smoothing parameter alpha and the initial level. Therefore, in total, you will penalise the model fit with 2 parameters.
The value of the parameters will affect the model fit part of the information criteria and not the penalty term. In general, if you are comparing two options that only differ in parameter values and not in model form (number of parameters), using information criteria is the same as using MSE. That is also why we do not optimise model parameters on AIC, as it makes no difference. Hope this clarifies it a bit more!
Hi Nikos,
Since ICs can only be used within a given family of models, for instance, ARIMA, can we use ICs to compare ARIMA models with different values of BoxCox transformation parameter lambda? In other orders, can an ARIMA model with lambda = 0 be compared with another ARIMA model with lambda = 0.30? The confusion stems from the fact that different lambda values transform the data differently.
Good question! Information criteria are based on the likelihood of the model. The likelihood is not invariant to scale changes (or any data transformations), so I would understand that it would be substantially different and therefore non-comparable.