N. Kourentzes, F. Petropoulos and J. R. Trapero, 2014, International Journal of Forecasting, 30: 291-302. http://dx.doi.org/10.1016/j.ijforecast.2013.09.006
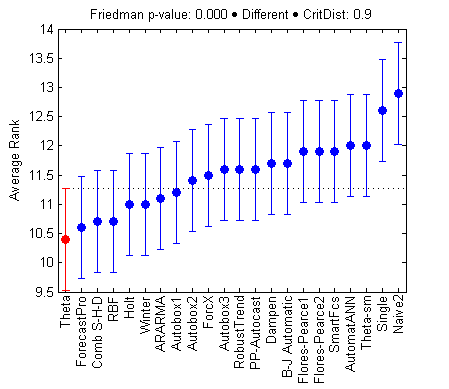
Identifying the most appropriate time series model to achieve a good forecasting accuracy is a challenging task. We propose a novel algorithm that aims to mitigate the importance of model selection, while increasing the accuracy. Multiple time series are constructed from the original time series, using temporal aggregation. These derivative series highlight different aspects of the original data, as temporal aggregation helps in strengthening or attenuating the signals of different time series components. In each series the appropriate exponential smoothing method is fitted and its respective time series components are forecasted. Subsequently, the time series components from each aggregation level are combined, and then used to construct the final forecast. This approach achieves a better estimation of the different time series components, through temporal aggregation, and reduces the importance of model selection through forecast combination. An empirical evaluation of the proposed framework demonstrates significant improvements in forecasting accuracy, especially for long-term forecasts.
Download paper. Paper summary slides available.
R code to replicate paper results can be found here.
R code to run MAPA on your data can be found here.
An online demo can be found here.
A simplified discussion of the article can be found here.
Errata: p. 296, Table 1, Md Trend case should be: l_{i+h}")