Over the years I have reviewed numerous papers that do not properly benchmark the various methods proposed. In my opinion if a paper has an empirical evaluation, then it must have appropriate benchmarks as well. Otherwise, one cannot claim that convincing empirical evidence is provided. The argument is simple: if the proposed method does not provide benefits over established benchmarks, what does it offer? Of course it is important to be careful not to focus just on forecasting accuracy, as there may be other benefits such as automation, robustness, computational efficiency, etc.
This is very relevant to practice as well. Often companies do not benchmark their forecasts and have little evidence if they their forecasts are fine, if they could improve, or how to improve. In my consultancy work this is often the first step that I take: benchmark the current process.
Of course, this is often easier said than done. One needs to have benchmarks implemented and these should not require far too much expertise to use. This is where all the work by various members of the community comes in handy! Currently there are multiple time series packages for R freely available. A lot of these are very easy to use.
Let us assume that we have a time series we want to forecast and that we have developed a new method. This is how easy it is to produce some benchmark forecasts:
> # Load the necessary libraries > library(forecast) > library(MAPA) > library(tsintermittent) > > # In-sample data: 'y.trn' > # Out-of sample: 'y.tst' > # Forecasts from our new brilliant method are stored in 'mymethod' > > # Start timer - Just to see how long this takes > tm <- proc.time() > > # Let's produce some benchmarks > frc <- array(NA,c(7,24)) # 7 benchmarks, forecast horizon 24 > > fit.ets <- ets(y.trn) > fit.arima <- auto.arima(y.trn) > fit.mapa <- mapaest(y.trn,paral=1,outplot=FALSE) > frc[1,] <- rep(y.trn[n-24],24) > frc[2,] <- forecast(fit.ets,h=24)$mean > frc[3,] <- forecast(fit.arima,h=24)$mean > frc[4,] <- mapafor(y.trn,fit.mapa,fh=24,ifh=0,outplot=FALSE)$outfor > frc[5,] <- crost(y.trn,h=24)$frc.out > frc[6,] <- crost(y.trn,h=24,type="sba")$frc.out > frc[7,] <- tsb(y.trn,h=24)$frc.out > rownames(frc) <- c("Naive","ETS","ARIMA","MAPA","Croston","SBA","TSB") > > # Calculate accuracy > PE <- (matrix(rep(y.tst,8),nrow=8,byrow=TRUE) - + rbind(mymethod,frc))/matrix(rep(y.tst,8),nrow=8,byrow=TRUE) > MAPE <- rowMeans(abs(PE))*100 > > # Stop timer > tm <- proc.time() - tm
So what we have here is forecasts from ‘mymethod’ and some benchmarks:
- Naive: hopefully our method predicts better than the random walk.
- ETS: state space exponential smoothing from the ‘forecast’ package.
- MAPA: multiple aggregation prediction algorithm using ets from the ‘MAPA’ package.
- Croston’s method: this is supposed to be used to intermittent data, but I just wanted to demonstrate how easy is to use this as a benchmark. This is from the ‘tsintermittent’ package.
- SBA: this a variant of Croston’s method from the ‘tsintermittent’ package.
- TSB: another intermittent demand method from the ‘tsintermittent’ package.
Of course not all benchmarks are appropriate, but I wanted to demonstrate how easy is to use them. Accuracy is assessed using Mean Absolute Percentage Error (MAPE), for t+1 up to t+24 forecasts.
> print(round(MAPE,2)) mymethod Naive ETS ARIMA MAPA Croston SBA TSB 5.76 7.37 6.00 7.34 5.59 5.76 7.07 7.26 > print(tm) user system elapsed 4.24 0.00 4.86
Apparently mymethod is pretty good, but in terms of accuracy MAPA seems to be doing better. Perhaps it is interesting to see that Croston’s method is not that bad, which makes sense considering that for non-intermittent data it is equivalent to exponential smoothing.
The whole benchmarking took very little coding and only 4.86 seconds to run. This could be sped up using parallel processing that both ‘forecast’ and ‘MAPA’ packages support. Of course we would prefer to have used rolling origin evaluation (cross-validation), and this could be implemented easily with a loop.
Here is the series and the various forecasts:
> cmp = rainbow(8, start = 0/6, end = 4/6)
> ts.plot(y.trn,y.tst,ts(t(rbind(mymethod,frc)),frequency=12,end=end(y.tst)),
+ col=c("black","black",cmp))
> legend("bottomleft",c("MyMethod",rownames(frc)),col=cmp,lty=1,ncol=2)
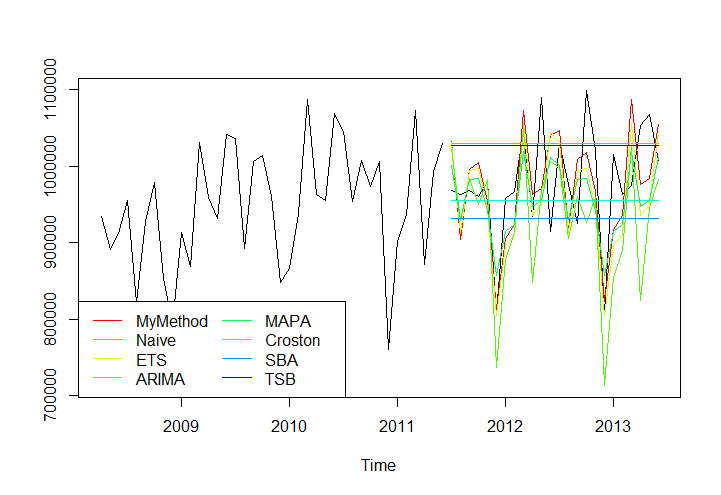
The example series is ‘referrals’ from the ‘MAPA’ package. In other posts here you can find more information about the functions in the MAPA and tsintermittent packages.
To conclude: benchmark your forecasts, it is easy and necessary!