Yes and… no! First, I should say that I am thinking of the common types of neural networks that are comprised by neurons that use some type of sigmoid transfer function, although the arguments discussed here are applicable to other types of neural networks. Before answering the question, let us first quickly summarise how typical neural networks function. Note that the discussion is done in a time series forecasting context, so some of the arguments here are specific to that and are not relevant to classification tasks!
1. Multilayer Perceptron (MLP) neural networks
MLPs are a basic form of neural networks. Having a good understanding of these can help one understand most types of neural networks, as typically other types are constructed by adding more connections (such as feedbacks or skip-layer/direct connections). Let us assume that we have three different inputs, (X1, X2, X3), which could be different variables or lags of the target variables. A MLP with a single hidden layer, with 5 hidden nodes and a single output layer can be visualised as in Fig. 1.
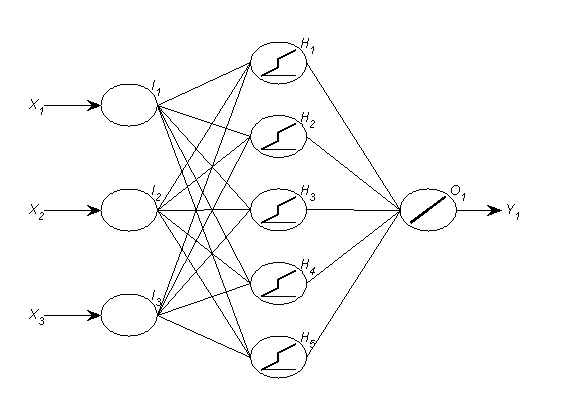
Fig. 1. MLP with 3 inputs, 5 hidden nodes arranged in a single layer and a single output node.
An input (for example X1) is passed and processed through all 5 hidden nodes (Hi), the results of which are combined in the output (O1). If you prefer, the formula is:
 \right) }") , (1)
, (1)
where b0 and a0,i are constants and bi and aj,i are weights for each input Xj and hidden node Hi. Looking carefully at either Eq. 1 or Fig. 1 we can observe that each neuron is a conventional regression that passes through a transfer function f() to become nonlinear. The neural network arranges several such neurons in a network, effectively passing the inputs through multiple (typically) nonlinear regressions and combining the results in the output node. This combination of several nonlinear regressions is what gives a neural network each approximation capabilities. With a sufficient number of nodes it is possible to approximate any function to an arbitrary degree of accuracy. Another interesting effect of this is that neural networks can encode multiple events using single binary dummy variables, as this paper demonstrates. We could add several hidden layers, resulting in a precursor to deep-learning. In principle we could make direct connections from the inputs to layers deeper in the network or the output directly (resulting in nonlinear-linear models) or feedback loops (resulting in recurrent networks).
The transfer function f() is typically either the logistic sigmoid or the hyperbolic tangent for regression problems. The output node typically uses a linear transfer function, acting as a conventional linear regression. To really understand how the input values are transformed to the network output, we need to understand how a single neuron functions.
2. Neurons
Consider a neuron as a nonlinear regression of the form (for the example with 3 inputs):
") . (2)
. (2)
If f() is the identity function, then (2) becomes a conventional linear regression. If f() is nonlinear then the magic starts! Depending on the values of the weights aj,i and the constant a0,i the behaviour of neuron changes substantially. To better understand this let us take the example of a single input neuron and visualise the different behaviours. In the following interactive example you can choose:
- the type of transfer function;
- the values of the input, weight and constant.
The first plot shows the input-output values, the plot of the transfer function and with cyan background the area of values that can be considered by the neuron given selected weight and constant. The second plot provides a view of the neuron function, given the transfer function, weight and constant. Observe that the weight controls the width of the neuron and the constant the location, along the transfer function.
What is quite important to note here is that both logistic sigmoid and hyperbolic tangent squash the input between two values and the output cannot increase or decrease indefinitely, as with the linear. Also the combination of weight and constant can result in different forms of nonlinearities or approximate linear behaviours. As a side note, although I do not see MLP as anything to do with simulating biological networks, the sigmoid-type transfer functions are partly inspired by the stimulated or not states of biological neurons.
By now two things should become evident:
- The scale of the inputs is very important for neural networks, as very large or small values result in the same constant output, essentially acting at the bounds of the neuron plots above. Although in theory it is possible to achieve the desired scaling using only appropriate weights and constants, training of networks is aided tremendously by scaling the inputs to a reasonable range, often close to [-1,1].
- With sigmoid type transfer functions it is impossible to achieve an ever increasing/decreasing range of outputs. So for example if we were to use as an input a vector (1, 2, 3, 4, 5, 6, …, n) the output would be squashed between [0, 1] or [-1, 1] depending on the transfer function, irrespectively of how large n is.
Of course, as Eq. (1) suggests, in a neural network the output of a neuron is multiplied by a weight and shifted by a constant, so it is relatively easy to achieve output values much greater than the bounds of a single neuron. Nonetheless, a network will still “saturate” and reach a minimum/maximum value and cannot decrease/increase perpetually, unless non-squashing neurons are used as well (this is for example a case where direct connections to a linear output become useful). An example of this follows.
Suppose we want to predict the future values of a deterministic upward trend with no noise, of the form: yt = xt and xt = (1, 2, 3, 4, …). We scale the observed values between [-1, 1] to facilitate the training of the neural network. We use only 80% of the values for training the network and the remaining 20% to test the performance of the forecasts (test set A). We train a network with 5 logistic hidden nodes and a single linear output. Fig. 2 provides the resulting network with the trained weights and constants.

Fig. 2. Trained network for predicting deterministic trend.
The single input (scaled xt) is fed to all five nodes. Observe that it is multiplied with different weights (black numbers) and shifted by different constants (blue numbers) at each node. When additional inputs are used, the inherent difficulty in interpreting all these weights together, makes neural networks to be considered as black boxes. Fig. 3 provides the observed yt and predicted neural network values. The network is able to provide a very good fit in the training set and for most of test set A, but as the values increase (test set B) we can see that the networks starts to saturate (the individual nodes reach the upper bounds of the values they can output and eventually the whole network) and the predicted trend tapers off. As we saw earlier, each sigmoid-type node has a maximum value it can output.
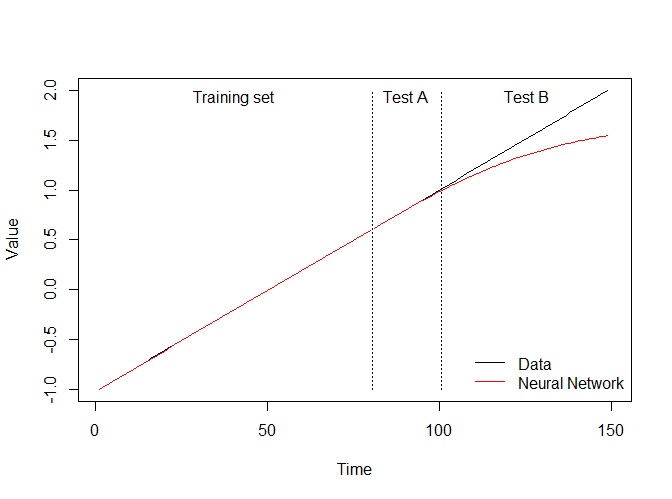
Fig. 3. Actuals and neural network values for the case of deterministic trend with no noise.
This raises a significant doubt whether neural networks can forecast trended time series, if they are unable to model such an easy case. One would argue that with careful scaling of data (see good fit in test set A) it is possible to predict trends, but that implies that one knows the range that the future values would be in, to accommodate them with appropriate scaling. This information is typically unknown, especially when the trend is stochastic in nature.
3. Forecasting trends
Although forecasting trends is problematic when using raw data, we can pre-process the time series to enable successful modelling. We can remove any trend through differencing. Much like with ARIMA modelling, we overcome the problem of requiring the network to provide ever increasing/decreasing values and therefore we can model such series. For example, considering one of the yearly M3 competition series we can produce the following forecast:

Fig. 4. Neural network forecast for a trending yearly M3 competition series.
Fig. 4 provides the actuals and forecasts after differencing and scaling is applied, the forecast is produced and subsequently differencing and scaling are reversed. However there are some limitations to consider:
- This approach implies a two stage model, where first zt = yt – yt-1 is constructed and then zt is modelled using neural networks. This imposes a set of modelling constraints that may be inappropriate.
- The neural network is capable of capturing nonlinearities. However if such nonlinearities are connected to the level, for example multiplicative seasonality, then by using differences we are making it very difficult for the network to approximate the underlying functional form.
- Differencing implies stochastic trend, which in principle is inappropriate when dealing with deterministic trend.
Therefore, it is fair to say that differencing is useful, but is by no means the only way to deal with trends and surely not always the best option. However, it is useful to understand how sigmoid-type neurons and networks are bound to fail in modelling raw trended time series. There have been several innovations in neural networks for forecasting, but most are bound by this limitation due to the transfer functions used.
So, can neural networks forecast trended time series? Fig. 4 suggests yes, but how to best do it is still an open question. Past research that I have been part of has shown that using differences is reliable and effective (for example see the specifications of neural networks here and here), even though there are unresolved problems with differencing. Surely just expecting the network to “learn” to forecasts trends is not enough.